- 2014年6月から7月のR関連ニュース
- ■(6月15日)RjpWikiのトップページからリンクされている,SASが無料で使えるようになりましたには驚いた。が,今となってはとくにSASであるメリットはないような気もする。検算用に一応入れておくというのはありかもしれないが,容量が大きすぎる。
- ■(6月18日)RjpWikiの掲示板に掲載されていた情報。物理乱数のためのRrdrandというパッケージを,なかまさんが作られた。喜んでinstall.packages("Rrdrand")したのだが,IvyBridge以降のCPUの機能を使うため,ぼくのvaio-saでは動作しなかった。Core i7といっても,もう旧世代機種なんだよなあ。
- ■(6月23日)RでLD50を求めるコーディング:
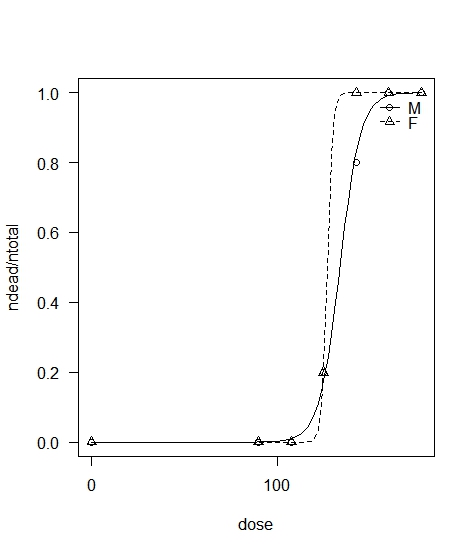 講義の関係で,RでLD50を求めるコーディングをしてみた。簡単にやるには,bstats,doBy,drcなどのパッケージを使うと楽だ。厚労省毒性試験データの文書に載っていた生データを分析するためのRコードを書いてみた。グラフは右のような感じ(なお,このコードとグラフには,「環境・食品・産業衛生学」の講義資料のページからもリンクしてある)。
講義の関係で,RでLD50を求めるコーディングをしてみた。簡単にやるには,bstats,doBy,drcなどのパッケージを使うと楽だ。厚労省毒性試験データの文書に載っていた生データを分析するためのRコードを書いてみた。グラフは右のような感じ(なお,このコードとグラフには,「環境・食品・産業衛生学」の講義資料のページからもリンクしてある)。 - ■(6月23日)新刊情報豊田秀樹『共分散構造分析[R編]―構造方程式モデリング―』東京図書, ISBN:978-4-489-02180-0を購入した。本書で知ったOnyxは,GUIで構造方程式モデリングができるフリーソフト。Rのlavaanパッケージと連動して使えるらしい。lavaanパッケージについては,本や,チュートリアルが参考になりそう。なお,Onyxからlavaanへの連携で解析すると,GUIで作ったモデルをすぐにRで実行できるのは利点だ。が,lavaan自体は順序カテゴリ変数を使ったり,(同じことだが)ポリコリック相関係数を使ったりすることも可能らしいのだが,Onyxにはそのためのオプションを見つけることができず,モデルを変える都度書き直すのならsemでコードを書き換えるのと変わらない。結局地道にやるしかないのか?
- ■(6月30日)元東工大の間瀬先生が,Rの各種公式マニュアルの翻訳を公開された。
- ■(7月7日)疾病負荷の指標の一つとして,障害調整生存年(DALYs)という概念が提案されているのだが,RのパッケージDALYとそのサポートサイトは素晴らしい。
- ■
- R-3.1.1リリースなど(2014年7月10日)
- ■R-3.1.1が予定通りにリリースされた(R-announce)。翌日にはCRANの統数研ミラーに入っていたので,早速ダウンロードした。
- 2014年7月から8月のR関連ニュース
- ■(7月22日)Amazonに注文していた,間瀬茂『Rプログラミングマニュアル[第2版]―Rバージョン3対応―』数理工学社/サイエンス社,ISBN 978-4-86481-015-9 (amazon)が届いた。
- ■(7月29日)海外のfmsbユーザから届いたコメント2件は,バージョンアップしないと対応できない内容だったので,とりあえずその旨をお答えするメールを送信した。1つはfitGM()が欠損値を含むデータに対してうまく動作しないことへの対応依頼で,もう1つはradarchart()の文字サイズだけ変えたいという要望であった。どちらも対処方法はすぐに頭に浮かんだが,多少手間がかかるので,喫緊の仕事が終わってからの対応になる。lifetable3()を含める(ついでにclifetable()にlifetable.fromqx(),lifetable3()にlifetable.fromlx()というエイリアスも作っておく)ことも忘れないようにしないといけない(lifetable2()もエイリアスがあった方が良いような気もするが,lifetable()に比べて年齢階級が可変長な場合や不規則なaxを与えたい場合にも使えるように,引数の与え方を拡張したものであって,計算の元にする死亡率データがmxである点は同一なので,エイリアスを作るほどでもないかと考え直した)。
- ■(7月30日)娘にプレゼントする前にと思い,結城浩『数学ガールの秘密ノート:丸い三角関数』を読んでいて,p.221の式を使って100ビット実数を使って円周率を10桁正しく出すには正何角形まで必要かを求めるためのRコードを書いてみた。このコードで使っているRmpfrパッケージについては,続・Rで数学をに少し書いたが,裏RjpWikiさんが,このコードの改良版のご提案とともに解説を書いてくださってありがたい。参考になった。
- ■(8月2日)Kobe.R#7に参加。最初の話題は,Tokyo.Rに参加して聞いてこられたことの報告。さすがTokyo.Rは内容も多岐にわたっていて凄いなあ。参考URLとしてhttp://estrellita.hatenablog.com/entry/2014/06/23/230657。 次の話題はサンプルデータの解析例の紹介。igraphを使ってとのこと。検索すると,R+igraphはhttp://www.slideshare.net/kztakemoto/r-seminar-on-igraphとか,https://sites.google.com/site/kztakemoto/r-seminar-on-igraphとかがヒットする。前処理の話ではNippon:::zen2hanを使って,混在している全角文字を半角に統一した点,igraphパッケージではgraph.data.frame()で生成したオブジェクトを操作するが,最短経路がget.all.shortest.paths()で得られるという話が印象的であった。12:00終了後,三宮駅近くの中華料理屋で昼食を食べつつ,雑談混じりのR話や解析話。 統数研の価値観国際比較調査がオープンデータになればいいなあという話があったが,これはhttp://www.worldvaluessurvey.org/wvs.jspとは別の調査なんだろうか?
- ■(8月4日)人口ピラミッドを重ね描きできないかという質問メールが届いていたので返事。現在のところ拙作pyramidパッケージではできないのだが,plotrixパッケージのpyramid.plot()関数にはadd=TRUEというオプションがあって重ね描きできるということで,サンプルコードを作ってみた。将来的には地図上にピラミッドを複数描画したいという野望があるので,pyramidパッケージは既存のグラフ上の任意の位置に任意のサイズで描画できるように改良したいのだが。fmsbパッケージに入っている日本人口データを使ったサンプルコードは下記の通り。
library(plotrix) library(fmsb) Ages <- 0:109 age <- c(ifelse((Ages%%10==0), paste(Ages), ""),"") pyramid.plot(Jpopl$M2000/100000, Jpopl$F2000/100000, labels=age, lxcol="#aaaaff", rxcol="#ffaaaa", unit="population/100000") pyramid.plot(Jpopl$M1950/100000, Jpopl$F1950/100000, lxcol="transparent", rxcol="transparent", add=TRUE) legend("topright", legend=c("2000年男性","2000年女性","1950年"), fill=c("#aaaaff", "#ffaaaa", "transparent"))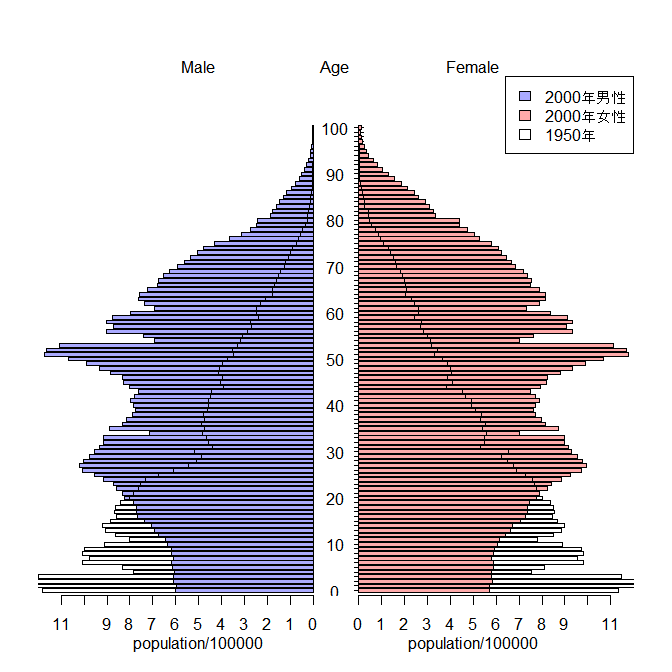
- ■(8月4日)fmsbパッケージを0.5.0に更新した。いくつか機能追加や修正点があるのだが,メールで届いた要望に応えたのは,radarchart()のラベルサイズ変更を可能にしたこととfitGM()の欠損値があるデータへの当てはめ方法を改善したこと。
- ■(8月13日,17日)日本の学校保健統計で使われている標準体重と肥満度の計算のための,LibreOfficeのワークシート例とRの関数定義と計算例を整理したので,アップロードしておく。ぼくはこういうコードで,ついVectorize()を使ってしまうのだが,本当はもっと正統派なやり方があるんだろうなあ。なお,この例からわかるように,まったく同じ身長・体重だとBMIは同じだが,年齢が違うだけで肥満度は大きく異なることがある。150cmで50kg(BMIは22.2)の女児は,17歳なら肥満度5.6,14歳でも9.1だが,11歳だと20.2で軽度肥満という判定になる。しかし実際には第二次性徴の発現は同年齢でも大きな多様性があるので,この判定が妥当とは限らないことには注意が必要である。個人レベルではもちろんだが,標準体重の計算式が2000年の日本人の値に基づいているので,集団レベルでも,例えば在日外国人とか,逆に海外在留日本人にこの式を適用していいのかどうかは慎重に考慮しなくてはいけない。なお,裏RjpWikiさんが,このRコードの改良案を書いてくださった。mapply()を使うという以上に,男女はifelse()で処理するより行列の引数にする方が筋だなあということに気づかせてくださった。感謝。
- ■(8月19日)EZR-1.25:自治医大の神田先生により,今日付で,EZRの1.25が公開されていた。Windows版インストーラに含まれるR本体が3.1.1になったので,簡単にEZRをインストールしたいWindowsユーザは,これを使えばいいと思う。
- Rでマルチレベル分析(2014年8月20日~21日)
- ■Rでマルチレベル分析を実行する方法を確認しておく必要に迫られたので,藤野善久・近藤尚己・竹内文乃『保健医療従事者のためのマルチレベル分析』診断と治療社,ISBN:978-4-7878-2053-2 (amazon)を再読。本書で使われているデータは出版社のサポートページからダウンロードできるのが便利だ。
- ■pp.69-70の多施設介入試験の分析をRとlmer()関数で実行するには,予めlme4パッケージをinstall.packages("lme4", dep=TRUE)でインストールしておき,library(lme4)でロードしてから,
とする。Stataの出力である図9-5の数値と比べると,Wald検定とのそのp値,固定効果(介入とベースラインのコレステロール値と切片)の係数のzとp値を除けば求めることができている。固定効果の係数については,zの代わりにt valueが提示されているけれども,本書にも書かれている通り,p値は敢えて表示していないのだそうだ。自由度が簡単には求められないからというのが大きな理由だが,それでもp値が欲しい場合は,このページに書かれているように,自由度が十分に大きいt分布は正規分布とほぼ同じだからと考えてpnorm()でp値を計算してしまうか,lmerTestパッケージをインストールしてlmer()関数を上書きしてsummary(lmer())だけでp値が得られるようにするか(SASのPROC MIXED同様,Satterthwaiteの近似で自由度とp値を計算してくれるらしい),pbkrtestパッケージを使ってKenward-Rogerの近似で自由度を出すかすると良いらしい(たぶん,この中ではlmerTestパッケージを使うのが楽そう)。x <- read.csv("http://www.shindan.co.jp/download/205300/cholesterol.csv")
res <- lmer(cholesterol ~ cholesterol_base + intervention + (1|clinic), data=x, REML=FALSE)
summary(res)
confint(res) - ■この他にRでマルチレベル分析をする方法としては,multilevelパッケージとnlmeパッケージを使う手もあるようだ。
- ■せっかくなので,ついでにこの例で,データの性状を見るための作図からマルチレベル分析まで,一通りの操作をするコードと作図と出力をまとめて示しておく。
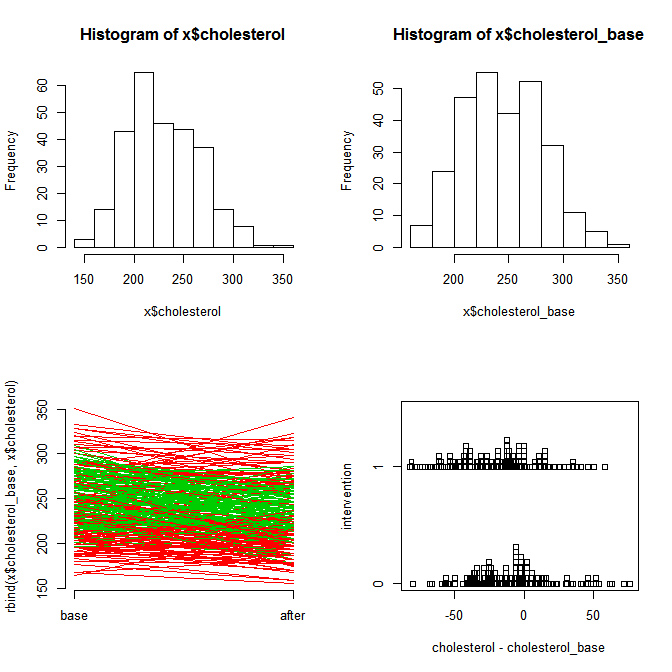
まず,介入の有無も施設の違いも無視して,前後でのコレステロール値の差があるかどうかだけを対応のあるt検定で調べてみると,
と,有意水準5%で統計学的に有意な差があるといえる。Paired t-test
data: x$cholesterol_base and x$cholesterol
t = 8.0383, df = 275, p-value = 2.713e-14
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
10.96801 18.08272
sample estimates:
mean of the differences
14.52536 
- ■前掲書p.69図9-4は,Stataによる回帰分析の結果である。ここでは,まず形式的に,介入の有無とベースラインのコレステロール値の,治療後のコレステロール値への交互作用効果を調べてみた。すると,
と,交互作用効果(cholesterol_base:as.factor(intervention)1の行)も有意水準5%で統計学的に有意であった。つまり,介入した群としなかった群の間で,ベースラインのコレステロール値と治療後のコレステロール値の関係が有意に異なっていた。もし解析の目的がベースラインコレステロール値と治療後コレステロール値の関係を調べることであれば,共分散分析によって修正平均を比較するよりも,2群別々に分析すべきということになるのだが,ここでの分析の目的は介入効果の評価なので,その方法では不適切である。Call:
lm(formula = cholesterol ~ cholesterol_base * as.factor(intervention), data = x)
Residuals:Min 1Q Median 3Q Max -52.619 -18.290 -2.475 16.547 87.592 Coefficients:
Estimate Std. Error t value Pr(>|t|) (Intercept) 41.05775 12.48988 3.287 0.00114 ** cholesterol_base 0.78941 0.05094 15.496 < 2e-16 *** as.factor(intervention)1 111.80484 24.42985 4.577 7.19e-06 *** cholesterol_base:as.factor(intervention)1 -0.48289 0.09812 -4.922 1.49e-06 *** ---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 25.97 on 272 degrees of freedom
Multiple R-squared: 0.483, Adjusted R-squared: 0.4773
F-statistic: 84.72 on 3 and 272 DF, p-value: < 2.2e-16 - ■そこで,図9-4と同じ結果を得るには交互作用効果を入れずにlm()関数で線形回帰すれば良い。
のようになる。Call:
lm(formula = cholesterol ~ cholesterol_base + as.factor(intervention), data = x)
Residuals:Min 1Q Median 3Q Max -51.755 -20.040 -2.563 16.194 91.172 Coefficients:
Estimate Std. Error t value Pr(>|t|) (Intercept) 72.49400 11.18021 6.484 4.16e-10 *** cholesterol_base 0.65923 0.04535 14.536 < 2e-16 *** as.factor(intervention)1 -7.42741 3.27763 -2.266 0.0242 * ---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 27.05 on 273 degrees of freedom
Multiple R-squared: 0.437, Adjusted R-squared: 0.4329
F-statistic: 106 on 2 and 273 DF, p-value: < 2.2e-16 
- しかし施設ごとに色を変えてプロットし直してみると,施設の効果がありそうに思えるので,これはマルチレベル分析にすべきである。lmerTestパッケージのlmer()関数により得られた結果オブジェクトをsummary()に渡せば,
という結果が得られる。Linear mixed model fit by maximum likelihood ['merModLmerTest']
Formula: cholesterol ~ cholesterol_base + intervention + (1 | clinic)
Data: xAIC BIC logLik deviance df.resid 2594.9 2613.0 -1292.4 2584.9 271 Scaled residuals:
Min 1Q Median 3Q Max -1.8741 -0.7486 -0.1038 0.5595 3.0095 Random effects:
Groups Name Variance Std.Dev. clinic (Intercept) 141.7 11.90 Residual 637.0 25.24 Number of obs: 276, groups: clinic, 10
Fixed effects:Estimate Std. Error df t value Pr(>|t|) (Intercept) 116.72600 13.27558 163.48000 8.793 2e-15 *** cholesterol_base 0.47132 0.05239 247.28000 8.997 <2e-16 *** intervention -1.74572 3.26249 275.74000 -0.535 0.593 ---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Correlation of Fixed Effects:(Intr) chlst_ cholstrl_bs -0.945 interventin 0.120 -0.241 - ■係数の信頼区間は,同じ結果オブジェクトをconfint()関数に渡せば得られる。昨日書いた通り,以上の手順で,Stataで得られる結果はほぼすべてRでも得られたと思う。本にも書かれていたが,マルチレベル分析にすると,回帰分析では有意であったinterventionの効果が有意でない,というのがポイントである。この場合,介入効果があったように見えていたのは,施設間差によるartefactであったと考えられる。
Computing profile confidence intervals ...
2.5 % 97.5 % .sig01 6.4527670 21.7732086 .sigma 23.2278626 27.5583053 (Intercept) 87.9180189 145.5631716 cholesterol_base 0.3581452 0.5886708 intervention -8.4035413 4.8428531 - Kobe.R#8(2014年8月30日)
- ■Kobe.R#8に参加した。部屋が変わっていたのに気づかず,開始が若干遅れたが,これまで最高の人数。初参加の人も多いので,開催主旨(+今回の内容予定)と自己紹介から。実際にデータを使って分析したり可視化したりというのがKobe.Rの特徴。今回はいろいろな新しいデータ紹介がある予定。以下,固有名詞が特定できないようにしたメモ。
- ■自己紹介から。業務では使っていなくて,これから学びたいという人が多い。分野としては機械学習とかビッグデータ解析とかの人が多い。Pythonによる機械学習の勉強会の主催者の方も初参加。PHPでwebサイト管理をしている方とか,スポーツ動作解析をしている人とか。
- ■最初の話題は前回の続きの通販データについて。分類は細かくない。受注データだけ。日時,アイテム番号,会員番号,価格。igraphを使って買った物の関連をみたというのが前回の話であった。最短経路の発見などもできた。データ元からのフィードバックとして,EC運営の考え方(2段階の消費)に基づき,このデータから知りたいことを列挙(ベストな新規獲得コスト,ベストな入り口商品,効果的な広告タイミング,売り上げ予測など)→それを明らかにするための解析方法を考える。(中澤感想:広告タイミングの効果を知るには実験が必要では?)そもそも広告タイミングデータはないので,購入間隔と購入金額などとの関係性が分析できれば良しとする。このデータではここまでしかわからないが,あと何のデータがあればこれがわかる,という形のsuggestionができれば,それでも良い。売り手側にとって理想的な購入パタンは,毎月一定量を買ってくれるような顧客。
- ■次の話題は商社の売り上げデータの分析。Rの基本機能だけを使って。
- ■次の話題は最尤法。観測データにポアソン分布を当てはめる事例での説明。尤度関数の値を最大化するパラメータを見つけることを目的とする手法。実際には計算の簡便性から対数尤度を最大化する。λで偏微分した値がゼロとなるλを求めれば良いので,そこを解くと,最も良く当てはまるλはデータの平均になる。平均値がλの最尤推定量になっている。複雑な分布の場合はこういう解析的な手法が使えないので,EMアルゴリズムなどを使うことができる(参照)。
- ■次の話題は疲労を見える化するという話。1000人弱の38項目の質問紙データ(+性別と自律神経機能指標と別の対象者についてVASによる自覚的疲労感)の因子分析と予測等。既に因子分析は論文になっている(7因子くらいあった)。線形モデルで自律神経機能を自覚症状から予測をするのは検討したがうまくいかなかった。機械学習など非線形はこれから。この勉強会でやってみたいとのこと。
- ■次の話題は神戸大海事科学の院生で,関西衛星会(仮)にも入っている方で,衛星画像とかGPSデータとかの話。小型衛星が今アツくて,さまざまなベンチャーが立ち上がっている。SpaceX,Planetary Resources,インターステラ,等々。各国がGPS衛星を打ち上げる理由には軍事的意図があるので,それによる制約がある。日本は準天頂軌道の「みちびき」という衛星を1機だけ打ち上げている。高精度だが,1日7~9時間しか受信できない。送信側と受信機側の時刻のズレから両者の距離が計算できるので,4機以上の衛星を受信できると正確な位置がわかる。軍事目的なら誤差数cmだが,民生用には時刻に敢えて誤差を入れているので,10メートルくらいの精度になる。複数の衛星や地上局電波を使って補正して精度を上げる試みがされていて,数十cmから数メートルの精度はスマホなどでも得られている。生データとしては$GPGGA,...という形で緯度経度や衛星数のデータが送られてくる。静止していても緯度経度情報は変動する(10メートルくらいはずれる)ので,それを考慮したデータ処理が必要になる。キューブサットを2016年春に打ち上げたいという構想があるので,協力者募集中とのこと。
- ■ここで12時を過ぎ,会場の時間制限で終了。大半の人が前回と同じ店で昼食をとってから解散となった(今回もいろいろ楽しい話題を提供してくださり,ありがとうございました>参加された皆様)。次回は9月21日が予定されているが参加できないのが残念。
- pyramidパッケージ機能追加(2014年9月4日~8日)→人口ピラミッドの項参照
- ■ふとpyramidパッケージでオーバーレイ描画させるためのアイディアを思いついて関数pyramidf()を作ってみた。par()からframeのデフォルトを受け取る部分がxaxpとyaxpではいけないのか,ずれてしまう問題が解決しないので,とりあえずオーバーレイには下記のように空plot()しておいて,同じframeを指定する必要がある。この問題が解決したらpyramidパッケージに組み込んで1.4版にするつもり。実行例としては,上でリンクしてあるpyramidf.Rを実行した後で下記のコードを実行(fmsbパッケージは日本人口を使うために呼び出すだけで,関数を使うわけではない)すると,その下の画像を描くことができる。
library(fmsb)
plot(c(0,100), c(0,100), type="n", frame=FALSE, axes=FALSE, xlab="", ylab="")
# overlay
pyramidf(data.frame(Jpopl$M1960, Jpopl$F1960, Jpopl$Age), frame=c(10, 90, 60, 100),
Clab="", Cstep=10, Laxis=0:3*5e+5, AxisFM="d")
pyramidf(data.frame(Jpopl$M2010, Jpopl$F2010, Jpopl$Age), frame=c(10, 90, 60, 100),
Clab="", Lcol=NA, Rcol=NA, Cstep=10, Laxis=0:3*5e+5, AxisFM="d")
# pararell
pyramidf(data.frame(Jpopl$M1960/10000, Jpopl$F1960/10000, Jpopl$Age), frame=c(0, 45, 0, 50), Clab="",
Cstep=10, Laxis=0:3*50, AxisFM="d", Llab="1960年男性(万人)", Rlab="1960年女性(万人)")
pyramidf(data.frame(Jpopl$M2010/10000, Jpopl$F2010/10000, Jpopl$Age), frame=c(55, 100, 0, 50), Clab="",
Cstep=10, Laxis=0:3*50, AxisFM="d", Llab="2010年男性(万人)", Rlab="2010年女性(万人)")
- ■この関数とmaptoolsを使えば,地図上に自治体単位で人口ピラミッドを書き込むことも可能になるはず。年齢区分をある程度大雑把にしないと見えないかもしれないが。
- ■(2014年9月8日追記)ということで,cranに入ったpyramid-1.4を使って,神戸市の区別に2010年国勢調査データにより5歳階級の人口ピラミッドを描く方法を人口ピラミッドの項に書いてみた。maptoolsパッケージで描ける地図から座標を取り出すのと,1つの区が複数のオブジェクトからなっているときに最大面積のオブジェクトの中心座標だけを得るようにするのに苦労した。
- デング熱感染が疑われる場所を地図上にプロット(2014年9月11日)
- ■岩田健太郎先生のtweetを拝見し,簡単な地図へのプロットを描いてみた(Rコード。ただし,#コメントで書いたようにESRI JapanからshpをダウンロードしてEpiMap(EpiInfoに入っているので無料で使えるけれども,ESRIからライセンスされているソフトで,とても操作がわかりやすい)などで加工しないと,このコードは実行できない。あと,地名から緯度経度情報への変換は,Geocodingを使って得た数値をハードコードしているが,GeocodingにはXMLを返すAPIがあるので,それを使うと情報更新が楽になると思う)。
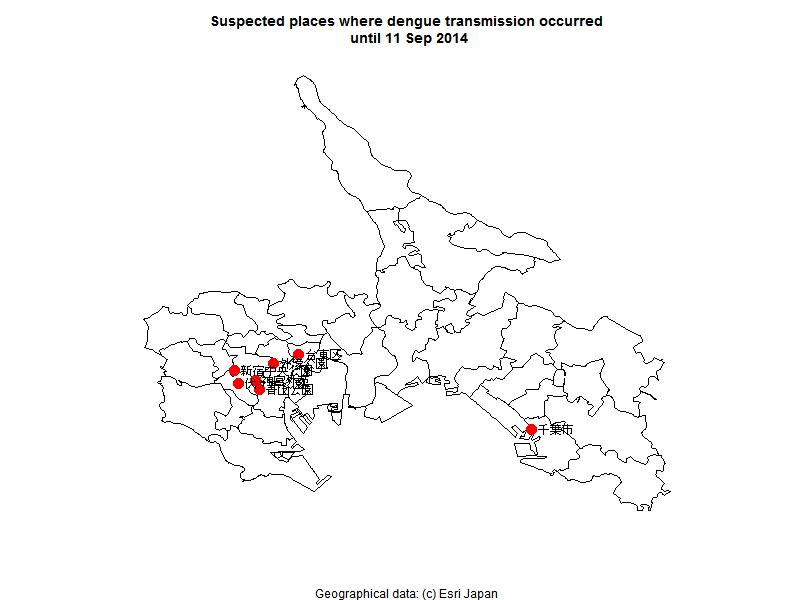
たぶん,厚労省サイトのデング熱についてからリンクされているデング熱の国内感染症例について(第十報)(現時点ではこれが最新だが,毎日のように新しい情報が追加された続報が掲載されている)のデータを入力してanimationパッケージを使って検出日ごとに推定感染場所のプロットを更新するようにすれば,岩田先生が参照されているエボラの地図のようなものも描けると思うし,Shinyサーバでやれば随時更新もできそう。暇がないのでやらないが,このRコードを自由に使っていただいて構わないので,実現してくださる方がいると嬉しい。 - ■これくらいの描画なら30分もあればできてしまうRとmaptoolsとEpiMap,それにネットでの情報入手のしやすさは,一昔前なら考えられないほど便利になったものだと思う。
- fmsb-0.5.1で2013年人口動態統計確定数データを追加(2014年9月15日)
- ■fmsbパッケージ内の人口動態統計データの更新作業として,Jvitalに数日前に発表された2013年確定数を追加するのとともに,2013年確定数のみだが都道府県別の人口動態データをJvital2013byPrefとして追加した。このデータを使った例としては,例えば,
とすれば,横軸を交通事故死亡率(人口10万対),縦軸を合計出生率TFRとした散布図が描けるし,死因別死亡率も入っているので,その都道府県別パタンを見たいと思えば,library(fmsb)
plot(TFR ~ CSM.TA, data=Jvital2013byPref)CSM <- Jvital2013byPref[, grep("CSM", names(Jvital2013byPref))]
OthPref <- CSM[-c(13, 20, 47), ]
TagPref <- CSM[c(13, 20, 47), ]
x <- rbind(OthPref, TagPref)
xc <- c(rep("lightgrey", 44),"deeppink","deepskyblue","navy")
xw <- c(rep(1, 44), rep(2, 3))
par(mar=c(6,2,4,2))
radarchart(x, maxmin=FALSE, pcol=xc, plty=1, plwd=xw,
vlabels=c("全死因","がん","心疾患","肺炎","脳血管疾患",
"老衰","事故","自殺","腎不全","COPD","大動脈瘤",
"肝疾患","糖尿病","敗血症","その他\n新生物",
"認知症","結核","交通事故"))
title(main="都道府県別死因別死亡率パタン(2013年人口動態統計)")
legend("bottomright", lty=1, lwd=c(2, 2, 2, 1),
col=c("deeppink","deepskyblue","navy","lightgrey"),
legend=c("東京","長野","沖縄","他道府県"))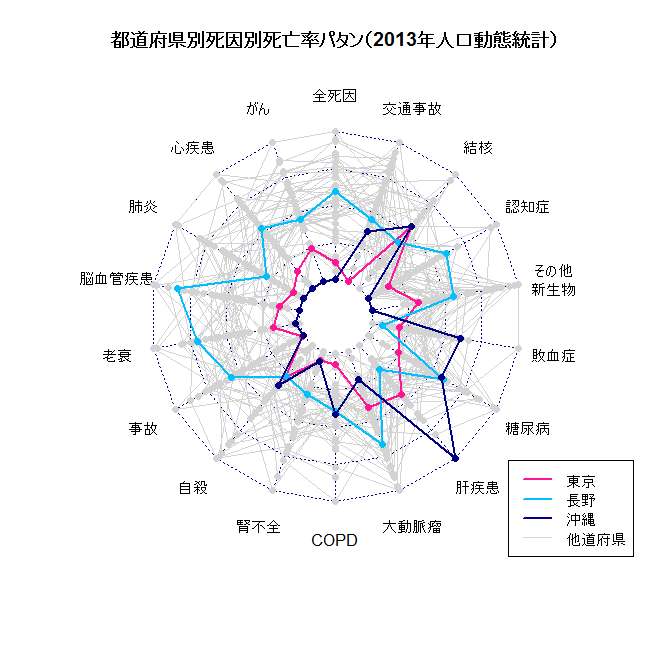
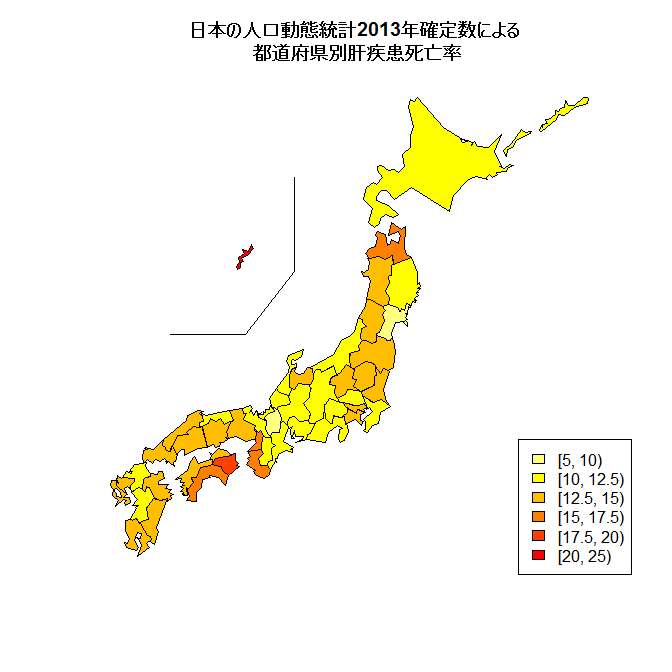
- ■このデータは,例えばNipponパッケージを使ってコロプレス図を描くような使い方もできる(library(Nippon); library(fmsb); JapanPrefecturesMap(col=rev(heat.colors(6))[cut(Jvital2013byPref$CSM.LIVD, c(5, 10, 12.5, 15, 17.5, 20, 25), right=FALSE)]); legend("bottomright", fill=rev(heat.colors(6)), legend=c("[5, 10)", "[10, 12.5)", "[12.5, 15)", "[15, 17.5)", "[17.5, 20)", "[20, 25)")); title(main="日本の人口動態統計2013年確定数による\n 都道府県別肝疾患死亡率")としてみると,肝疾患死亡率で塗り分けた地図が描かれる)。ただし,死因別死亡で年齢調整をしていないため,損失余命でみた場合とまったく特徴が異なることには注意されたい。沖縄や東京の値が小さいのは年齢構造が若いことの寄与が大きいと思う。肝疾患による死亡は,それでも全都道府県の中で沖縄が最も高い値になっているので,公衆衛生政策上,注目する必要があると思う。
- ■このデータ追加も含め,fmsbパッケージを0.5.1にアップデートし,cranで公開した。詳細はこちらをご覧頂きたい。
- パッケージの情報確認(2014年9月18日)
- ■たけしょうさんからコメントいただいた通り,fmsbパッケージもpyramidパッケージも,library()やrequire()でロードするだけでは,どのバージョンがインストールされているのかわからないが,packageDescription("fmsb")などとすればバージョン情報(というか,DESCRIPTIONファイルに書いてある内容)が表示される。mgcvパッケージみたいにロードしたときにバージョン情報を含むメッセージが表示されるようにした方が親切かもしれないが,unix的な文化からすると,可能な限り不要な情報はデフォルトでは表示しない方がcoolなので,とりあえず,この方法でバージョン確認していただけるとありがたい。ちなみに,現時点での最新版は,fmsbが0.5.1,pyramidが1.4である。
- ■なお,guestさんからいただいたコメントにより,library(help=fmsb)と打つことで,バージョン情報のみならずコンテンツまで表示されることがわかった。
- gmpパッケージ関連の話題2つ(2014年9月22~23日)
- ■裏RjpWikiの「多倍長精度計算結果を見やすく出力」と,その元になった,r-statistics-fanの日記の「Rで多倍長精度計算~とりあえず10000の階乗を計算してみる」には明記されていないが,もちろん10000の階乗を計算するだけなら,library(gmp); factorial(as.bigz(10000))とするのが簡単。たぶん,整数の多倍長演算にはRmpfrパッケージよりgmpパッケージの方が向いていると思う。sink("factorial10000.txt")のようにしてから実行すれば,指定した名前のテキストファイルに結果を書き出せる。その後で出力をコンソールに戻すにはsink()とすれば良い。10桁ごとにスペースを入れて100桁ごとに改行させたければ次のようにすると思う。
library(gmp)
longfact <- function(x, n=100, m=10) {
z <- factorial(as.bigz(x))
siz <- ceiling(log10(z))
p <- n - (siz %% n)
res <- paste(rep("_", p), sep="", collapse="")
res <- paste(res, as.character(z), sep="", collapse="")
q <- (siz + p)/m
for (i in 1:q) {
cat(substr(res, (i*m)-m+1, (i*m)))
cat(ifelse((i %% m)==0, " \n", " "))
}
}
longfact(10000) - ■「r-statistics-fanの日記」のスコットランド独立賛成票が素数~Rで素数をチェックする関数色々を拝読し,library(gmp); n[sapply(sapply(n, factorize), length)==1] とか?とtweetしておいたら,記事に追記してくださった。gmpパッケージの高性能さは感動的。
- ■鵯記にguestさんからいただいたコメントの通り,gmpパッケージにおけるfactorial(as.bigz(10000))は,たぶん実際にはfactorialZ(10000)を実行している。Rの思想としては型を指定し総称関数に渡すのが普遍的と思うので,ぼくは今後も最初の書き方をすると思うが。
- maps, mapdata, mapplotsパッケージ(2014年9月25日)
- ■地図上に円グラフを表示することは,Excelでさえできるのに,maptoolsパッケージを使って地図を描いた上に,指定座標を中心とする指定半径の円グラフを書かせようと思うと,R標準のpie()ではできない。plotrixパッケージならあるだろうと思ったが中心座標と半径を指定して円グラフを描かせる機能は見当たらなかった。
- ■Rと連携する有料ソフトではNaviイントラエースとかAdam-Liteといったものが見つかるのだが,この程度の機能だけのために払う金額としては高すぎる。
- ■radarchart()のフレーム内描画版を作るついでに,fmsbパッケージに実装してみようか? たぶん簡単にできると思うんだが……。と考えたものの,その前に既存のものは本当にないのだろうか? と思ってcranを探したら,R2G2パッケージのFancyPies()とか,mapplotsパッケージのadd.pie()といった先駆者がいた(とくに後者については,解説つきの用例も見つけた)。まあ,これがあれば作らなくてもいいかな。
- ■なお,上にリンクした解説付きの用例の文書を読んで調べたら,mapsパッケージとmapdataパッケージをインストールすれば,州境入りUSA,フランス,イタリア,省境入り中国,都道府県境入り日本,ニュージーランド,国境入り世界地図の地理情報データが入っていることがわかった(有名な話かもしれないが,ぼくは知らなかった)。今書いている人口分析の本では,ESRIやDIVA-GISからのシェイプファイルダウンロードだけでなく,これらのパッケージを使う方法も説明しようと思う。
- Rにおけるデータの型とデータ構造(2014年9月25日)
- ■たけしょうさんのtweetから,Rのデータ型とデータ構造関連の話として,群大の講義では1回目と2回目に説明していたとtweetした。
- ■群大の統計演習ではRでコーディングすることを教えていたので型やデータ構造の知識も必須だったが(もっとも,S4クラスまでは必須ではないと思う),神戸大の大学院ではEZRで演習しているので,この辺のことは系統的には教えていない。
- mapplots用例(2014年9月29日)
- ■忘れないうちにmapplotsの使用例を作っておこうと思い,神戸市区別主要統計からExcelファイルをダウンロードした。ここから産業別人口割合のデータを使って地図上に円グラフをプロットするコードを書いてみたが(alphaチャンネルを使った透過色での塗りつぶし設定のパッケージscalesも使ってみた),あまりぱっとしないグラフになってしまった。

- EZR-1.26(2014年9月29日)
- ■9月29日付けで,EZRがバージョン1.26に更新されていた。
- 効果量(2014年10月15日)
- ■裏RjpWikiさんの効果量と,そこからリンクされている記事は大変興味深い。
- CRAN登録パッケージ数が6000超(2014年10月29日)
- ■CRANの登録パッケージ数が6,000を超えたとのこと。メインテナ人数は3,444人なので,1人平均2つ弱といえる。ぼくがやっているのはpyramidとfmsbの2つだから,まあ平均的ということか。
- R-3.1.2リリース(2014年10月31日,11月6日,11月18日)
- ■Peter Dalgaardさんから,R-3.1.2 is released.というR-announceメールが流れた。予定通りだ。
- ■講義終了後,フロンティア館717に移動してRの3.1.1をアンインストールしてから3.1.2をインストールし,常用ライブラリをインストールし,RStudioも更新した。環境変数のPathも書き換えた。とくに不具合はなさそうだ。
- ■R-3.1.2は,Windowsではまったく問題なく使えているのだが,MacOS Xにインストールした院生(留学生)の話によると,3.1.2にしてしまうと,semをインストールしようとしたときに適切なバージョンがないというエラーメッセージが出て困るとのこと。もしかしたらsemはまだMac OS X環境では3.1.2に対応してないとか? 時間の問題とは思うが。
- vdmR(2014年11月9日)
- ■生態学的研究の例としてグラフを作ろうと思ってwebを検索していたら,藤野さんが以前のR研究集会で発表されていた,福岡県の統計資料をインタラクティブに表示するシステムをvdmRというパッケージにしてcranで公開されていることを知った。素晴らしい。
- EZRの新しい本(2014年11月11日)
- ■自治医大の神田先生の新刊『初心者でもすぐにできるフリー統計ソフトEZR(Easy R)で誰でも簡単統計解析』が出ていることを知った。
- 標準化偏回帰係数の計算について(2014年11月19日,11月21日)
- ■Rでの標準化偏回帰係数の計算について,ここの方法は今でもできるが,欠損値対応するためにこのコード内で示した式はエラーになるので,原因を調べたら,listへの処理の仕方が厳密になったようで,sd(res$model)とする代わりに,sapply(res$model, sd)とすれば計算できることがわかった。
- ■最新版のRでエラーが出るままのコードでは具合が悪いので,重回帰分析の解析例(VIFで多重共線性をチェックし,標準化偏回帰係数を求め,AICでモデルの当てはまりの悪さを調べる)を更新した。
- R研究集会2014(2014年11月29日)
- ■今年も統数研でR研究集会が行われた。自分の発表はスライドだけでは情報量が不十分だが,Rで学ぶ人口分析のページを今後充実させる予定。他の方の発表(メモ,*は中澤の感想とか。内容は無保証)は,大変興味深かった。
- 因子分析(2014年12月3日)
- ■Rで因子分析~商用統計ソフトでできないあれこれ~は,とても新しくて実践的と思う。有用な情報公開ありがとうございます(>清水さん)。なお,因子分析って何? という方には、石田先生の『とある弁当屋2……』(因子分析入門pdfへのリンク付の書評)がお勧め。
- オッズ比とp値,信頼区間についてのメモ(2014年12月27日)
- ■ソロモン諸島滞在中にtwitterで奥村先生とやりとりした件だが,Rothman大先生とp値関数の作り方を巡ってやりとりした話とリンクしていて,"Epidemiology: An Introduction"でも,断面研究でp値を出すときには2x2表の独立性を帰無仮説としているので,連続性の修正無しのカイ二乗検定のp値と一致しているけれども,オッズ比の信頼区間をp値関数にするときには取り得るオッズ比の値のそれぞれを帰無仮説としたp値を計算することによってp値関数と信頼区間関数が一致する。帰無仮説が異なるため,当然p値は違う値になる。つまり,95%信頼区間が1を跨いでいるのにp値が0.05より小さいというようなことも起こりうる。
- ■この点,vcdパッケージは偉くて,xに検定したい2x2表が行列として付値してあるなら,library(vcd)の後に,oddsratio(x, log=FALSE)とすればオッズ比の点推定量が得られ,confint(oddsratio(x, log=FALSE))とすれば95%信頼区間が得られ(基本的に対数変換して正規分布に近づけた標準誤差に正規分布のパーセント点を掛け,点推定量の対数にプラスマイナスしてからexp()に渡すという式なので,fmsbのoddsratio()やepitoolsのoddsratio.wald()の結果と一致する),summary(oddsratio(x, log=TRUE))とすれば(log=TRUEがデフォルトなので,つけなくても良い)p値が得られるけれども,このp値は信頼区間と矛盾を起こさない(この辺りの話は,『Rによる保健医療データ解析演習』[草稿pdf]のp.163-p.164に既に書いていた)。Prof. Rothmanからアドヴァイスをいただいてfmsbパッケージのpvalueplot()関数を修正した([1], [2])ときにわかっていたことだが,間違いというわけではないので(誤解を生じやすいし整合しないのは美しくないが)放置していた。次のバージョンアップ時には,2種類のp値とそれぞれの意味がはっきりわかるように出力するように,oddsratio()とriskratio()を書き換えよう。
- 参考リンク(2014年12月29日)
- ■Twitterで目にしたR関係の参考リンク:[1],[2],[3]。
- Rtools新バージョン(2015年1月7日)
- ■[r-devel]で,Rtools for Windowsの新バージョンが公開されたとのメールが流れてきた。暇を見てインストールしなくては。
- 重回帰分析関連(2015年1月27日,2月8日)
- ■メールで,重回帰分析から強制投入する変数がある変数選択をさせる方法の問い合わせがあり,調べたらleapsパッケージのregsubsets()関数でforce.inオプション(lmの中と同様にモデルを指定し,強制投入する変数名を文字列ベクトルとして指定する。変数選択の方法は,デフォルトがexhaustive,即ち総当たり法だが,method="backward"とかも可能だし,nvmaxオプションで採択する最大変数数も指定できる)を使えばできることがわかった。regsubsets()関数だけではp値などは出ないが,summary()をとったオブジェクトのadjr2とかbicでベストモデルを決め,もう一度lm()をすればいい。暇があったら簡易マニュアルを作るか。
- ■リッジ回帰などについて
- Hadleyさん関連(2015年2月4日,5日)
- ■R bloggersに載っていた記事の元にコメントしたのだが,海外でも所謂「ハドラー」さんの勢力は拡大中と思われる。どこが直感的にわかりやすいというのか,ぼくには良く理解できないが,たぶん一度使い始めると,日本でも大流行中のパイプ系の関数は,作図におけるggplot2というかgridグラフィックスと同じように,麻薬的な魅力があるのだろうなあ。
- ■@kohsukeさんのtweetを見て,dplyrを使わないでやってみたらどうなるかと思ってやってしまったので,採録しておく。要は,自分が使っているRの環境で,インストールされている全パッケージのうち,作者にHadley Wickhamさんを含んでいるパッケージの割合を計算し,ハドリー指数(Hadley Index)と呼ぼうという提案であった。それくらいハドラーさんはR世界を席巻しているということだな。
- ■RTした@kohskeさん作ハドリー指数をdplyrの無い環境で
mean(grepl("Hadley", sapply(rownames(installed.packages()), packageDescription, fields="Author")))
0.065だった - ■(承前)関数化してみる
PAIDX <- function(X="Hadley") { mean(grepl(X, sapply(rownames(installed.packages()), packageDescription, fields="Author"))) } - ■(承前)今作った関数を使ってみる sapply(c("Hadley", "Nakazawa", "Fox", "Kanda", "Hyndman", "Ripley", "Ihaka", "Dalgaard", "Hornik", "Murdoch"), PAIDX)
- ■(承前)xに付値してcat(paste(names(x),round(x,3)),"\n")
Hadley 0.065 Nakazawa 0.009 Fox 0.028 Kanda 0.005 Hyndman 0.037 Ripley 0.074 Ihaka 0.009 後略 - ■(承前)確かに自分が作ったパッケージは2つだけで、全部で230余りのパッケージをインストールしてあるから、0.009という数字は当然なのだが、なんだか悔しい。まあ、Rの始祖Ihakaさんと同じ数字だからいいか。
- ■ちなみに,Hadley Wickhamさん自身は,0.235という,物凄い値を叩きだしている。
- 多重比較メモ(2015年2月5日,2月8日,2月26日)
- ■永田靖: 多重比較法の実際, 応用統計学 27: 93-108, 1998.は,統計的多重比較法の適用において実務家から寄せられた疑問点を材料に,「多重比較法に関する誤解・誤用」,「多重比較法を用いる際の注意点」などについて検討した論文。対照群が2つある場合の多重比較についての詳しい議論や,多重比較を考慮したサンプルサイズの設計などは大変参考になる。1998年なので,FDR法には言及がなかった。
- ■奥村先生のtweetから,Rothmanが検定の多重性の調整は不要と言っている論文のpdf
- ■リンクメモ:不等分散の場合に使う青木先生が実装されたGames-Howell法と,それを英文で紹介しているページ―これとかこれ。弘前大の「改変Rコマンダー」がTukeyに青木先生の関数を使っているのでGames-Howellができる。
- ■物凄い数の文献をレビューして4つのパタンに整理した多重比較のオーバービュー論文
- sem参考論文(2015年2月5日)
- ■semの相談を受けた。どうしてもfitを良くするには試行錯誤が必要だが,そのときの方針の参考として去年出たレビュー論文を読んで貰うことにした。役に立ちそうな内容だったが,当時はmod.indices()だった関数が既にdepricatedで,現在はmodIndices()を使うので,そこは修正が必要だった。
- Rに「もしかして」機能を(2015年2月10日)
- ■久保さんのtweetで知った,Rに「もしかして」機能を追加するは凄いアイディアだと思う。Core teamが取り入れればいいのに。
- R-3.1.3とR-3.2.0リリース予告(2015年2月12日)
- ■Dr. Peter Dalgaardから,3月9日にR-3.1.3が,4月16日にR-3.2.0がリリース予定というアナウンスがあった。パッケージメインテナ(とくに推奨パッケージのメインテナ)は変更が必要ならこれに間に合わせるようにというお達しであった。たぶんfmsbとpyramidは変更しなくても動くとは思うが,fmsbはいろいろアップデートしたい機能が溜まっているので,この機会にバージョンアップしよう。2月中はいろいろ忙しいので,3月7日と8日の土日が勝負だな。
- Brunner-Munzel検定(2015年2月20日)
- ■Brunner-Munzel検定についての三重大学奥村先生の解説記事とhoxo_mさんの解説記事。独立2群の分布の位置の差の検定として,平均値が分布の位置の代表値として適切な場合はWelchの検定でいいが,中央値を使った方がいい場合は,Wilcoxonの順位和検定よりも,Brunner-Munzel検定(あるいはそれを改良した並べ換えBrunner-Munzel検定)の方が良いということが丁寧に説明されている。2000年に書かれた論文に基づく新しい検定法なのでまだマイナーだが,今後広まるだろう。Rではlawstatパッケージに入っているとのことだが,思想的にもわかりやすいので,そのうちCore teamが本体に取り入れてくれるんではないだろうか。
- 2冊の絶版本の最終版をpdf化して公開(2015年2月26日)
- ■絶版になった『Rによる統計解析の基礎』第8版のpdf(ただし出版社が作ってくれた綺麗な図などは除く)を作ってアップロード。
- ■絶版になった『Rによる保健医療データ解析演習』URL修正済みpdf(サポートページに掲載した修正事項は概ね取り入れ済みだが,出版社が作ってくれた綺麗な図などは入っていない)もアップロードした。
- ■ご意見・ご質問は,このページにコメントくださるか,Twitterで@MinatoNakazawaにコメントくださるか,直接メールくださると有り難い(多忙のためレスポンスは遅くなるかもしれないが,その辺りはご容赦いただきたい)。
- ■次はエビデンスベーストヘルスケア特講Iのテキストのアップデートだな。
- ■先週知ったBrunner-Munzel検定についての記述も入れたいし,多重比較周辺の話も追記しておきたい(今月初めにメモしたこととか,青木先生が実装されたGames-Howell法と,それを英文で紹介しているページ―これとかこれとか―,さらには弘前大の「改変Rコマンダー」がTukeyに青木先生の関数を使っているのでGames-Howellができることとか,物凄い数の文献をレビューして4つのパタンに整理した多重比較のオーバービュー論文等々)。
- 絶版書籍最終版pdfへのコメント受付(2015年2月26日)
- ■なお,『Rによる統計解析の基礎』第8版pdf及び『Rによる保健医療データ解析演習』エラー修正済みpdfについてのご意見・ご質問は,このページにコメントくださるか,Twitterで@MinatoNakazawaにコメントくださるか,直接メールくださると有り難い(多忙のためレスポンスは遅くなるかもしれないが,その辺りはご容赦いただきたい)。
- R Projectのサイトリニューアル(2015年3月5日)
- ■The R Projectサイトがリニューアルされた。外見はあまり変わっていないが,内部的にはかなり変わったらしい。
- R-3.1.3リリース(2015年3月9日)
- ■R-3.1.3(コード名:"Smooth Sidewalk")が予定通りリリースされたとのこと。リリースノートをざっと見た感じでは,あまり大きな変更はなさそう。
- 『美味しんぼ「鼻血問題」に答える』読了感想から,オッズ比計算確認(2015年3月23日)
- ■鼻血に関してだけいえば,牧野淳一郎さんの本で書かれているような(立ち読み用pdfを見るだけでも興味深いが,購入予定。tweetもされていた)放射性物質の微粒子による局所曝露で起こっているのか(本書で雁屋さんもこれに似たメカニズムを想定している),心理的ストレスが主因なのか,それとも自己診断による発見兆候バイアスなのかは別として,雁屋さん自身が鼻血を経験したことと,取材時に聴いた「鼻血が増えた」という言説を元に作品に反映させたことは当初から明らかで,確かに『美味しんぼ』に嘘は書いていない。多くの医師や科学者が,鼻血を出すほどの放射線といえば1 Sv以上で出血傾向というメカニズムしか考えずに,「ありえない」と批判したのは,鼻血が全身影響の現れであるという物語を読み取ってしまったからだろう。疫学や公衆衛生学の立場からは,実際に多いのかデータを取り,多ければそれは何故なのかと分析を進めるのが正当な方法である。
- ■本書にも引用されているが,このページからリンクされている2013年9月6日付けの報告書に掲載されている,岡山大学津田教授らが積極的疫学調査として行った2012年11月の質問紙調査結果の表3,表4から抜粋すると,
項目\集団 滋賀県長浜市木之本町 福島県双葉町 宮城県丸森町筆甫地区 対象者数 7056 6730 733 回答者数
(回収率)3775
(56.1%)3872
(54.9%)637
(86.9%)熱
(有症割合%)50
(1.3)58
(1.5)5
(0.8)咳・痰
(有症割合%)386
(10.3)521
(13.7)59
(9.5)歯茎の腫れ・出血
(有症割合%)142
(3.8)212
(5.6)17
(2.7)鼻血
(有症割合%)14
(0.4)43
(1.1)5
(0.8)
というデータがある。ここでいう有症割合は,保健統計でいえば国民生活基礎調査の有訴者率に相当する。国民生活基礎調査には鼻血の有訴者率がないが,他の症状を見ると,2013年調査結果では熱が8.5‰,咳・痰が49.2‰,歯茎の腫れ・出血が18.9‰となっており,本調査結果はこれよりもおしなべて高い。対象者の年齢の内訳が書かれていないのではっきりとはわからないが,年齢構成の違いの影響かもしれないし,質問紙の作り方が国民生活基礎調査とは違っていて,答えやすかったのかもしれない(回収率が高かった宮城県丸森町でも全国データより有訴者率が高めなので,回収率の影響はそれほどないと考えられる)。しかし,いずれにせよ,東日本大震災・津波・原発事故の影響を受けていないと考えられる木之本町でとくに有訴者率が低いということはなく,対照群としての適格性を疑う根拠はない。 - ■報告書に書かれているオッズ比(鼻血について,滋賀県長浜市木之本町を対照として福島県双葉町が3.8 [95%信頼区間は1.8~8.1],宮城県丸森町が3.5 [同1.2~10.5])は,成人のみについて,年齢,性別,喫煙等を調整した多重ロジスティック回帰分析の結果なので,全年齢を対象にした単純なオッズ比とは必ずしも一致しないが,Rで単純なオッズ比を計算してみても滋賀県長浜市木之本町を対照とした福島県双葉町のオッズ比については似たような値になる(ただし,鼻血の有訴者割合についてのこの単純な分析では,宮城県丸森町はそのどちらとも統計的に有意な差があるとはいえないことになるが)。
- ■多重ロジスティック回帰分析の方が妥当だと考えた場合,一つ謎なのは,この集団の選び方である。報告書に書かれていないので理由はわからないが,なぜ放射線量が高い地域を含む宮城県丸森町を選んだのだろうか。結果から有意に高い有訴者率がいえても,放射線の直接・間接の影響なのか,地震や津波の影響なのかを区別して論じることができない。例えば岩手県で同様な調査をしていれば,地震や津波の影響は受けているけれども放射線影響は少ない対照集団が得られ,この調査の福島県双葉町集団や宮城県丸森町集団との比較により,放射線の影響なのかどうかを検討できたはず(牧野さんが想定されたような直接影響なのか,ストレスのような間接影響なのかは依然として不明だが)なのが残念な資料だった。けれども,福島県双葉町での鼻血の有症割合が高かったというデータは,この報告書から事実として示されたといえる。もっとも,それが何故なのかというと,既に書いたように,少なくとも3つ以上の理由が考えられるので,この結果から放射線の直接影響をいうのは拙速に過ぎると思うが,『美味しんぼ』福島の真実<22>で山岡士郎が鼻血を出した描写と,その後の元市長の発言内容に嘘はなかったと言える。
- seroincidenceパッケージ(2015年4月12日)
- ■昨日メモしそびれたが,CRAN新着のseroincidenceパッケージは,ECDCのプロジェクトで開発された(?),横断研究で得られた血清抗体陽性割合から感染力(force of infection)を推定するツールの実装らしい。
- ggplot2論争?(2015年4月15日)
- ■ggplot2論争?は,裏RjpWikiさんとkohskeさんのフォーカスが違うので。たぶん噛み合っていない。裏RjpWikiさんの問題意識はggplot2というよりもgridへの批判で,kohskeさんの反論は探索的にグラフィカルなデータ表示ができるというggplot2固有の思想の擁護になっていると思う。Rの描画におけるbaseとgridという2つのシステムが相互乗り入れできない(実はリンク先を読むと,gridBaseパッケージを使えばbaseの描画コードをgridに持ち込むのは簡単らしいが)のが悲劇の元で(敢えて悲劇と書く。こう書いてしまうと,"where scaling is maintained properly on resizing, nested graphs are desired or more interactivity is needed."というニーズに応えるためにgridを開発したPaul Murrelさんには申し訳ないが),ggplot2をgridでなくbaseに載せてくれたら,このような問題は起こらなかったのではないか。世間ではよくgridに描画されたグラフが美しいと評されるので,そのデフォルトの描画が美しいと思えない裏RjpWikiさんは(ぼくも裏RjpWikiさんと同感だが),そこを批判しているけれども,gridのより大きな問題は(interactivityのために仕方なかったのかもしれないが),描画デバイスがbaseと非互換なので,描画後の細かい加工が不便なことだと思う。逆に,たしかにbaseの描画は関数ごとにオプション指定の方法なども違っている(例えばpyramidパッケージで人口ピラミッドを描く関数のオプション指定などを汎用化するのは困難なので,これはある程度仕方ないことだと思う)けれども,methods("plot")とすればわかるように,オブジェクトのもっているクラスに応じてplot(object)という総称的な呼び出しで適切な描画ができるようにする思想は,元々Rに備わっていた。例えば,線形回帰の関数lm()が返すオブジェクトはlmというクラスを持っているので,このオブジェクト名をresとすると,summary(res)とすれば自動的にsummary.lm(res)が呼び出され,線形回帰の結果として必要な情報をまとめて表示してくれるし,plot(res)とすればgetS3method("plot","lm")で定義が見えるplot.lm()が呼び出されて,4種類のプロットを順次提示してくれる。だから,kohskeさんが例示してくれている探索的なグラフ表示オブジェクトに適切なクラス定義をして,plot.*という形でそれに適した描画をbaseのグラフィックデバイスに出力してくれる形の関数定義をすることは可能だったはずで,そういう定義の仕方をしてくれたら,できあがったグラフへのbaseの低レベル描画の追加による加工が簡単だっただろうから,grid以前からのRユーザにもggplot2はより広く受け入れられたと思う。うん,まあ,コード的には無駄が多くなりそうな気がするので,ggplot2の開発陣がgridを選んだ理由も理解できるけれども。
- R-3.2.0リリース(2015年4月16日~18日)
- ■(4月16日)メールを見たら,R-3.2.0がリリースされたというアナウンスがあった。3.1.3をインストールしたばかりなので,少し様子見するかな。
- ■(4月18日)6:00にリクライニングした椅子の上で目が覚めたら,バックアップ作業は終わっていた。統数研ミラーを見たら,既にR-3.2.0があったのでダウンロード。様子見と書いたけれども,ついでにインストールもしてしまおう。とりあえず,先にラボのPCにインストールするんだな……というわけで,ラボのPCへのR-3.2.0のインストールを済ませ,ついでにパッケージ群をインストールしてEZRの自動起動アイコンを作ってみたら,ちゃんと動いた。
- xml2パッケージなど(2015年4月21日)
- ■CRANberriesでNew CRAN package xml2 with initial version 0.1.0を見て,xml2という,あのHadleyさんらの新しいパッケージがCRANに載ったことを知った。read_xml()でXMLを読める。奥村さんが紹介していたreadxパッケージといい,最近のR先端開発業界のfocusはデータ読み込みの改善に向かっているのか。
- エビデンスベーストヘルスケア特講テキストをさらに少しだけ改善しアップロードした。今年は留学生が1人受講しているので,英語版も数年ぶりに更新しなくてはならないのだが,この間,日本語版コンテンツを相当増やしているので,まだとてもできない。
- Rで決定木(2015年4月24日)
- ■Rで決定木分析をする方法について問い合わせメールが来たので,調べて返事した。せっかくなので以下採録。
EZRはRの追加パッケージの一つであり,EZRの中には決定木分析のメニューはありません。EZRのコンセプトは,よく使われる医学統計手法をメニューから選ぶだけで実行可能にするというものなので,データマイニング(探索的データ解析ともいえます)の一つである決定木分析が含まれていないのは当然です。
Rの追加パッケージのうち,決定木分析に使われるのはtree,rpart,mvpart,partykitなどのようです。豊田秀樹(2008)『データマイニング入門―Rで学ぶ最新データ解析―』東京図書の第3章に詳しい説明があります。
webではこのpdfなどが,このテキスト第3章を使ったセミナー資料のようです。
同志社大学金さんのエストレーラ連載記事も参考になると思います。
決定木のRパッケージについてのレビューもありました。
例えばpartykitを使うなら(#より後は注釈なので無視してください),Rコンソールに
install.packages("partykit", dep=TRUE) # パッケージのインストール(ネット接続要)
library(partykit) # partykitパッケージを呼び出す。Rを起動するたびに必要
example(HuntingSpiders)
と打てば決定木が表示されます。 - 箱ひげ図のひげの長さとRの基本グラフについての動画(2015年4月27日)
- ■三中さんのこのtweetを見て(関連してこのページの幹葉表示の図解の美しさは素晴らしいと思った),箱ひげ図のヒゲの上端と下端が最大最小だと外れ値がわかりにくいので元のテューキーの方法の方が優れているし,どうしてそんな指導がされているのかと思ったが,高校の学習指導要領を調べたら,五数要約値のグラフ化と教えられているようだった。
- ■ちなみにEZRでのヒゲの描き方は4種類のオプションから選べて,中には最大最小も入っている。素のRに入っているboxplot()ではrange=0というオプションを付けるとヒゲの上端下端が最大最小になるけれども,rangeのデフォルト値はrange=1.5で,これはテューキーの方法通りに,四分位範囲の1.5倍をヒゲにし,それが最大や最小を超えるときは最大や最小までしかヒゲを引かないという描画をしてくれる。
- ■このブログで紹介されている,YouTube上の約1時間の動画は,baseへのプロット方法についてがメイン。珍しい。
- 日本の20~39歳女性の出生への寄与の推移(2015年5月9日)
- ■バスの中で学士会会報No.912を開いたら,最初に一月午餐会講演をされた増田寛也さんの『「人口減少社会」における効果的な少子化対策』が掲載されていた。人口移動の予測の困難さなどにもきちんと触れられていたことと,「東京オリンピックに向けて,東京一極集中はますます加速する」という予想の下で行われた予測が『消滅可能性都市896全リスト』につながったことを明記されていたのは良かった。ただ,日本創成会議提言の1番目「人口減少の要因は,20~39歳の若い女性の減少と,地方から大都市圏(特に東京圏)への若者の流出という二点である」は少し注意が必要と思う。

20~39歳女性の数が減っているだけではなく,年齢別出生率そのものが低下しているのだし,上図に示すように(これを描くRコード),たしかに20-39歳の出生が全出生に占める割合は減少傾向とはいえ,ほぼ95%であるには違いないけれども,20代の出生は著しく低下し,それを30代の寄与が高まることで補っている状況といえる。とくに東京の出生率自体が著しく低いので,増田さんも書かれている通り,「地方の人口減少には東京一極集中が大きく影響している」からといって,東京への流入を止めたら東京の人口は著しく減少し産業が維持できなくなる可能性がある。概ね数値的な現状把握としては妥当だけれども,掲げられたビジョンが「効果的な少子化対策」なのかどうかは疑問。最後の提言「地域力向上」は美しいが画餅感が否めない。 - SEIRモデルの学習用コード(2015年5月18日)
- ■講義のため,SEIRモデルを割合で連続量として数値計算する場合と,離散量として二項乱数を使ってシミュレーションする場合を簡単に比較できるようなRコードを書いたのだが,オブジェクト名を後で変えたため,当初アップロードしたコードがエラーを吐いて焦った。
- R-3.2.1リリース情報(2015年5月18日)
- ■R-3.2.1が6月18日リリース予定だそうだ。
- このページの更新(2015年5月24日)
- ■2月末以来,久々にこのページを更新した。この約3ヶ月の間に鵯記に書き散らしたR関係の情報を拾ってまとめただけだが,量が多かったなあ。
- ■ついでにメインマシンであるDynabook R83のRをR-3.2.0に更新した。例によってR-3.1.3をアンインストールし,R-3.2.0をインストールしてから,起動アイコンに設定してあるパスを変え,環境変数のパスを変える。さらにwebに載せてある自分がいつも使っているパッケージをまとめてインストールするためのスクリプトをダウンロードして実行した。かなり依存パッケージが多くてサイズも大きいものもあり,待ち時間が長かった(もちろん,他の仕事をしていればいいのだが,その間はRが使えない)。
- MetaCran(2015年5月25日)
- ■RdというRの開発者向けメーリングリストで知ったが,MetaCranという,cranに登録されているパッケージの検索/一覧サイトは便利だと思う。multiple imputationで検索したら,多重代入法のためのパッケージがたくさんあることに驚いた。
- UNdata,基本グラフィックパラメータ,Games-Howell法(2015年5月26-27日)
- ■R-bloggersの,Open data sets you can use with Rという記事で紹介されているUNdataは凄い。講義に使えそう。
- ■Rの基本グラフィクス環境におけるパラメータのうち,使用頻度が高いと思われるものの一覧だそうだ。以前似たようなものを書いた気がするのだが,もはやどこにやってしまったか覚えていない。低レベルグラフィクスを描くときは描画領域を設定するmarとかomaを操作できると便利なことがあるが,さすがにマニアックすぎるせいか,触れられていないなあ。
- ■多重比較のGames-Howell法だが,userfriendlyscienceというパッケージ(プロジェクトのサイト)のposthocTGH()という関数のmethod="games-howell"オプションで可能になったのでインストールしてみた。このパッケージは,SPSSに実装されている機能とほぼ等価なものをRに追加し,さらに進んだ機能を初心者にやさしく使えるようにすることによって,SPSSからRに移行したい人たちにとってRを利用しやすくすることを目指している(意訳)とのこと。例えば,SPSSのデータを読み込むにはgetData()という関数があり,regr()という関数がSPSSの回帰分析と同様の出力をするラッパーとして提供されているそうだ。なお,多重比較のGames-Howell法はposthocTGH()で直接実行する他にも,oneway()という一元配置分散分析を実行する関数でposthoc="games-howell"オプションを指定することでも実行可能らしい。
- R-3.2.1リリース(2015年6月18日)
- ■R-3.2.1が予定通りリリースされた。
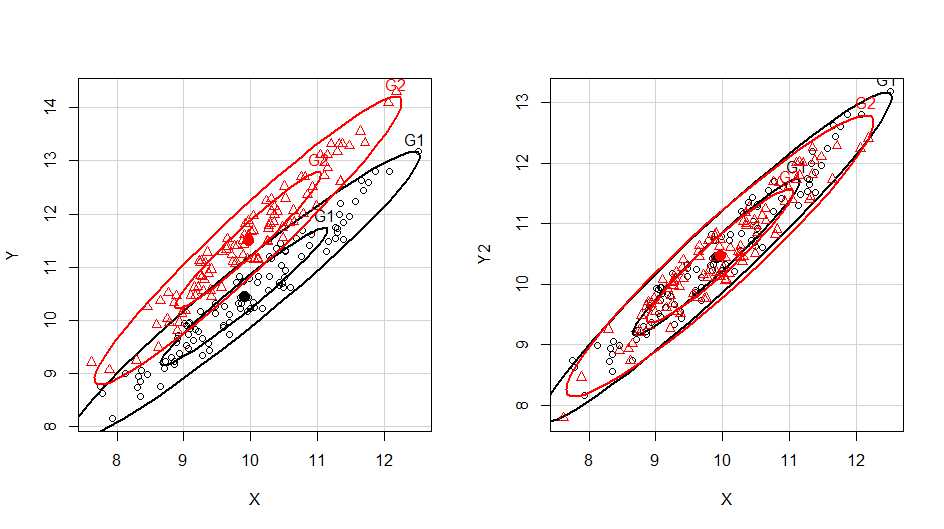
- 集中楕円とHotellingのT2(2015年6月24-26日)
- ■エビデンスベーストヘルスケア特講Iの終了後,集中楕円(確率楕円)とHotellingのT2について質問があった。 前者はEZRでもロードされているcarパッケージにdataEllipse()関数があるが,後者はHotellingパッケージを導入する必要があった。使い方を示す参考コードとグラフを載せておく。
- ■この内容を反映させるため,エビデンスベーストヘルスケア特講Iのテキストを更新した。
- ■自分の常用しているパッケージのインストール用スクリプトにHotellingパッケージを追加した。
- 生存時間分析/Crawley本の2nd Ed.(2015年6月27-30日)
- ■2013年12月の奥村泰之さんのスライド「生存時間分析の書き方」(StatGuild Inc.さんのtweetから)
- ■微分積分餅死文という方のtweetで,Crawley御大の『統計学:Rを用いた入門書』(原題:Statistics: An Introduction using R)の名文が紹介されていたので,確かにあの本は良かったけれども,その後どうなっただろう? と思って検索したら,今年第2版が出ていた。Amazon.co.jpからKindle版ならすぐに入手できることがわかったが,Kindle版だと数式を見るのに少々難があるという情報をいただいたので,やっぱりPbk版を注文するかなあ。Amazon.co.jpから注文すると2~3週間かかるらしいが。Crawley御大は"The R Book"という大部な技術指南書も書かれていて,そちらは2013年に第2版が出ているのは知っていたので,技術書に比べて理論書の方が息が長くて古くならないなあと思っていた。今回ちょっと刺激を受けたので,ぼくも,『Rによる統計解析の基礎』は2004年に書いて第8版まで小改訂だけしてきた(出版社の事情で絶版になったので第8版をpdfにして公開している)のを,大改訂して再出版する意欲が少しだけ出た。
Correspondence to: minato-nakazawa[at]umin.net.